Fahrassistenzsystem: Viel hilft nicht immer viel
Minderwertige Datensätze erhöhen die Unfallgefahr bei Fahrassistenzsystemen: Ist Quantität wirklich die beste Lösung für das Training hochfunktionaler ADAS?

Die Annotation der Objekte ist oftmals ungenau, da viele Personen mit unterschiedlichen Herangehensweisen an den Datensätzen arbeiten. Um dies auszugleichen, werden die Bounding Boxes großzügiger als nötig festgelegt und überlappen sich häufig.
Foto: ARRK Engineering
Fahrassistenzsysteme (ADAS) sind heutzutage nicht nur ein Standardaccessoire in jedem Neuwagen, sondern auch ein wichtiger Meilenstein auf dem Weg zum autonomen Fahren. Sei es die Fahrspur und den Abstand zum vorausfahrenden Fahrzeug halten oder an engen Stellen einparken: Je mehr die technischen Helfer selbstständig können sollen, desto besser wollen die dem System zugrunde liegenden neuronalen Netze dafür trainiert werden. Entsprechend wachsen auch die verwendeten Datensätze immer weiter an. Doch das führt zu einer Frage: Inwiefern spiegeln die Trainingsdaten überhaupt die operativen Einsatzbereiche der ADAS wider? Dies ist oftmals zweitrangig und wird nur selten überprüft.
Um die Fehleranfälligkeit der Systeme dennoch zu reduzieren, wurde bisher lediglich die Quantität der Daten erhöht. Das Ergebnis sind unnötig komplexe, langwierige und dadurch auch ineffiziente Entwicklungsprozesse. ARRK Engineering hat daher einen Ansatz entwickelt, mit dem sich die Modelle im Hinblick auf konkrete operative Einsatzbereiche und dabei relevante Szenarien, beispielsweise Stadtverkehr oder Autobahnen, analysieren lassen. Fehlerhafte oder die Realität verzerrende Daten können korrigiert oder entfernt und die ADAS auf diese Weise zielgenau, zuverlässig und zugleich ressourceneffizient trainiert werden.
Immer mehr Fahrzeuge mit Assistenzsystemen
Namhafte OEMs machen es, Mobility-Startups tun es ihnen gleich und Verbraucher wollen es: In immer mehr Fahrzeugen werden Fahrassistenzsysteme der Automatisierungsstufen 2 und 3 verbaut. Somit verlassen sich tagtäglich zahlreiche Verkehrsteilnehmer auf Spurhalteassistenten, automatische Einparkhilfen und Abstandsregeltempomaten, auch bekannt unter der englischen Bezeichnung Adaptive Cruise Control (ACC). Die allgemeine Sicherheit auf den Straßen – und damit die Unversehrtheit sämtlicher Verkehrsteilnehmer – hängt also maßgeblich von der einwandfreien Funktion der Systeme ab. Um diese sicherzustellen, werden deren neuronale Netze mithilfe riesiger Datensätze trainiert. Die Modelle sollen sämtliche mögliche Situationen abbilden, in die das Fahrzeug im alltäglichen Verkehrsgeschehen geraten kann, und so als Erkennungs- und Berechnungsgrundlage für die selbstständigen Reaktionen des ADAS im Feld dienen.
Riesige Datensätze: der Teufelskreis der Masse
Je komplexer die Funktionalitäten der unterschiedlichen ADAS sind, desto spezifischere Datensätze werden für deren Trainings benötigt. Um all die individuellen Verkehrssituationen abzudecken, wurden die Datenmodelle in den letzten Jahren immer weiter vergrößert. Der Fokus lag dabei primär auf Masse, also der bloßen Anzahl der enthaltenen Aufnahmestunden oder der annotierten Objekte bei unterschiedlichen Wetterlagen und Lichtverhältnissen. Dies führt jedoch unweigerlich dazu, dass sich auch der Anteil der fehlerhaften oder für einen bestimmten operativen Einsatzbereich schlichtweg unpassenden Daten proportional erhöht. Um sicherzustellen, dass die neuentwickelten ADAS weiterhin zuverlässig funktionieren, wurde dieses Qualitätsdefizit wiederum mit Quantität kompensiert – ein Teufelskreis. Die Folge sind bereits heute sehr lange Entwicklungszeiten mit vielen Iterationsschleifen, in denen allein die Trainings der neuronalen Netze mehrere Wochen beanspruchen.
Die Lösung für die Automobilindustrie, um diesem Dilemma zu entfliehen, besteht darin, den Fokus weg von der Quantität und hin zur Qualität der Datensätze zu verschieben. Daher, haben die Machine Learning-Spezialisten von ARRK Engineering einen Ansatz entwickelt, um die Prozesse im Hinblick auf einen operativen Einsatzbereich zu validieren und bei Bedarf entsprechend zu korrigieren. Auf diese Weise lässt sich das Development effizienter gestalten und, wichtiger noch, auch die funktionale Sicherheit der ADAS erhöhen – eine Voraussetzung für ihre zukünftige Weiterentwicklung auch in höhere Levels des autonomen Fahrens.
Beispiel ACC: Analyse der Datensätze hinsichtlich der Trajektorienplanung
Als Untersuchungsbeispiel wurde die ADAS-Funktion ACC ausgewählt. Sie hält das Fahrzeug mit einer bestimmten Geschwindigkeit auf der Fahrspur und stellt dabei stets einen ausreichenden Abstand zu anderen Verkehrsteilnehmern und Hindernissen sicher. Dafür berechnet das System zu jedem erkannten Objekt die sogenannte Time-To-Collision (TTC). Sinkt diese unter einen definierten Schwellenwert, dann reagiert das Fahrzeug entsprechend mit Brems- oder Ausweichmanövern. Dabei gilt: Je größer die Geschwindigkeitsdifferenz zwischen dem Fahrzeug selbst und einem davor befindlichen Objekt ist, desto kürzer fällt die TTC aus und desto früher muss das ACC reagieren.
Aufgrund dieser Relation ist es notwendig, dass das System zum Beispiel Objekte auf Autobahnen in deutlich größerer Entfernung zuverlässig erkennt, wohingegen der nahe Bereich, in dem sich ein potentielles Hindernis befinden kann, im städtischen Umfeld größer ist. Doch sind die ADAS-Funktionen der unterschiedlichen Hersteller dazu überhaupt in der Lage? Um dies herauszufinden, legten die Forschenden den Fokus auf die Trajektorienplanung. Für den Einsatzort Deutschland definierten sie drei Fahrszenarien mit unterschiedlichen Geschwindigkeitsbegrenzungen und entsprechend variierenden Anforderungen an das ACC: Autobahn (130 km/h Richtgeschwindigkeit), Landstraße (max. 100 km/h) und Stadtverkehr (max. 50 km/h).
Sechs Datensätze analysiert
Für ihre Analyse zogen die Experten insgesamt sechs Datensätze heran, darunter große Modelle, die seit Jahren von namhaften OEMs genutzt werden: ONCE, nuScenes, A2D2, LyftLevel5, Waymo und Kitti. Ziel der Untersuchung war zunächst, die statistische Verteilung der annotierten Objekte herauszufinden, die das System erkennen kann. Dabei spielten etwa die Größe der zur Annotation genutzten Bounding Boxes, das Verhältnis zwischen ihrer Größe und Entfernung zueinander, der Abstand zwischen dem Fahrzeug und anderen Objekten sowie deren relative Positionsverteilung auf dem Sensor und der optische Fluss der Bildsequenzen eine Rolle. Mithilfe dieser Parameter ermittelten die Forschenden, wie präzise die Objekte überhaupt annotiert und entsprechend mit Bounding Boxes versehen wurden. Zudem untersuchten sie, wie gut die Kamerasensoren der Fahrzeuge auf ihre operativen Einsatzbereiche eingestellt waren und welchen Anteil beispielsweise Stehphasen ausmachen, bei denen über einen längeren Zeitraum (nahezu) statische Bilder erfasst wurden.
Optimierung der untersuchten Datensätze
Die Ergebnisse der Analysen und die daraus abgeleitete Qualität der Datensätze überraschten die Machine Learning-Spezialisten von ARRK Engineering – und zwar in negativer Hinsicht. So entdeckten sie etwa unerwartet viele statische Bilder aus Stau- und Stehphasen, welche nicht als solche markiert waren und daher die Detektor-Trainings der ACCs negativ beeinflussen können. Im Gegensatz dazu ließen alle untersuchten Datenmodelle annotierte Objekte in größeren Entfernungen ab rund 100 m komplett vermissen.

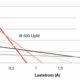
Die Machine Learning-Spezialisten entdeckten bei ihrer Analyse viele statische Bilder aus Stau- und Stehphasen, welche nicht als solche markiert waren und daher die Detektor-Trainings der ACCs negativ beeinflussen können. Im Gegensatz dazu ließen alle untersuchten Datenmodelle annotierte Objekte in größeren Entfernungen ab rund 100 m komplett vermissen. Grafik: ARRK Engineering
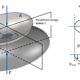
Aufgrund der kurzen TTC bei Geschwindigkeiten von etwa 130 km/h ist das zuverlässige Erkennen von derart weit entfernten Hindernissen allerdings unabdingbar für den sicheren Einsatz des ADAS auf Autobahnen in der Bundesrepublik. Zudem ist die Annotation der Objekte oftmals ungenau, da viele Personen mit unterschiedlichen Herangehensweisen an den Datensätzen arbeiten. Um dies auszugleichen, werden die Bounding Boxes großzügiger als nötig festgelegt und überlappen sich häufig. Dies macht es für die Systeme wiederum schwieriger, Hindernisse auszumachen, und verlängert die Trainingsprozesse drastisch. Heatmaps, welche die Verteilung der annotierten Objekte über die gesamte Sensorfläche visualisieren, machen darüber hinaus deutlich, dass 99,9% der Objekte lediglich in der unteren Hälfte erfasst wurden. Auch in puncto Ausrichtung der Kamerasensoren herrscht somit Verbesserungsbedarf.

Heatmaps visualisieren die Verteilung der annotierten Objekte über die gesamte Sensorfläche und zeigen, dass 99,9 Prozent der Objekte lediglich in der unteren Hälfte erfasst werden. Grafik: ARRK Engineering
Ziel der Forschenden ist es nunmehr, die mangelhafte Qualität der Datensätze im Hinblick auf die Entwicklung von ADAS der Levels 2 und 3 zu steigern. Daher entwickelten sie einen Ansatz, um die Modelle in Bezug auf die operativen Einsatzbereiche der Systeme zu validieren und ihre Defizite entsprechend zu korrigieren. Indem zum Beispiel Aufnahmen mit deutlich überlappenden Bounding Boxes sowie statische Bilder eliminiert werden, lässt sich die Präzision und Generalisierung der Detektortrainings erhöhen.

Zudem ermöglichen die Untersuchungsergebnisse, die Tauglichkeit eines Datensatzes für ein konkretes Einsatzszenario überhaupt erst festzustellen und bei den Trainings entsprechend zu berücksichtigen bzw. zu ergänzen. Im Fall des ACC betrifft dies etwa Fahrten innerorts, auf dem Land oder auf Autobahnen. Indem die Kamerasensoren zudem besser auf das tatsächliche Verkehrsgeschehen hin ausgerichtet werden, lassen sich die Effizienz der Berechnungen und somit auch die Reaktionszeit des ACC verbessern.
Höhere Sicherheit auf den Straßen aufgrund validierter Datensätze
Datensätze, die mit den neuentwickelten Ansätzen von ARRK Engineering validiert werden, ermöglichen es, die erforderlichen Iterationsschleifen im Trainingsprozess und somit die gesamte Entwicklungsdauer der ADAS maßgeblich zu reduzieren. Durch effizientere Trainings lässt sich also bereits im Development wertvolle Zeit einsparen. Hinzu kommt, dass präzise auf ihren operativen Einsatzbereich hin trainierte Systeme auch eine höhere funktionale Sicherheit aufweisen. So kann das ACC im praktischen Einsatz etwa bewegte Objekte sowie stillstehende Hindernisse zuverlässiger erkennen und rechtzeitig entsprechende Brems- oder Ausweichmanöver initiieren. Insbesondere im Hinblick darauf, dass sich auf dem Weg zum autonomen Fahren in Zukunft immer mehr und hochfunktionalere ADAS auf unseren Straßen bewegen, erhöht sich so die allgemeine Sicherheit im täglichen Straßenverkehr.
Das Paper wurde im Rahmen der Konferenz SafeAI 2023 vorgestellt: https://safeai.webs.upv.es/

Václav Diviš
Senior Expert Machine Learning
ARRK Engineering GmbH
info@arrk-enginerring.com
www.arrk-engineering.com
Foto: ARRK Engineering