Hohes Potenzial für lernende Systeme in logistischen Entscheidungsprozessen
Entscheidungsprobleme in der Planung und Steuerung industrieller Lieferketten sind durch eine Vielzahl von Zielgrößen, Restriktionen und Einflussfaktoren bestimmt. Die Komplexität der Entscheidungen steigt durch das zunehmend dynamische und vernetze Umfeld sowie die wachsende Bedeutung von Flexibilität, Zuverlässigkeit und Effizienz. Bisherige unterstützende Softwaresysteme stoßen hierbei an ihre Grenzen. Sie basieren vor allem auf Simulationen, mathematischen Optimierungen und regelbasierten Verfahren, die nur sehr begrenzt in der Lage sind, komplexe Entscheidungssituationen unter Unsicherheit zu bewerkstelligen und flexibel auf neue Umfeldbedingungen zu reagieren. Eine eigenständige Anpassung im Sinne eines „Lernens“ ist diesen Lösungen vorenthalten, sondern kann nur durch den Eingriff des Menschen im Rahmen einer Softwareanpassung erfolgen.

Machine Learning und Künstliche Intelligenz haben viel Potenzial bei logistischen Entscheidungsprozessen.
Foto: panthermedia.net/Jirsak
Machine Learning und Künstliche Intelligenz
Die zunehmende Datenverfügbarkeit im Zuge der industriellen Digitalisierung sowie die steigende Leistung der Informationsverarbeitung, insbesondere durch Techniken des „Cloud Computings“, ermöglichen die jahrzehntelange angestrebte Realisierung solch intelligenter Systeme. Die Grundlage dieser innovativen Lösungen bilden datenbasierte Verfahren des Maschinellen Lernens („Machine Learning“ bzw. ML). ML versteht sich als bedeutendes Teilgebiet der Künstlichen Intelligenz (KI) und ist ein Fundament für weitere KI-Bereiche, wie Bilderkennung, NLP und Robotik. Im Gegensatz zu den bisherigen modellbasierten Ansätzen erkennen ML-Algorithmen komplexe Zusammenhänge der Realität in Daten und wenden diese mittels verschiedener Funktionen auf neue Problemstellungen an. Die kontinuierliche Erweiterung der maschinenseitigen „Erfahrungen“, d. h. das Training der Algorithmen, erfolgt hierbei mittels der Bereitstellung neuer Datensätze und kann automatisiert werden.
Für die Nutzung von datenbasierten Technologien ergeben sich im industriellen Kontext vielseitige Einsatzfelder 1. Insbesondere vielschichtige Logistiknetzwerke der Industrie mit ihren komplexen Entscheidungsprozessen und den hohen Skalierungsmöglichkeiten zeigen ein hohes Potenzial für ML, bisherige Planungs- und Steuerungssysteme zu ergänzen oder gar zu ersetzen. Trotz eines Bruttowertschöpfungspotenzials von knapp 32 Milliarden Euro durch KI-Anwendungen im produzierenden Gewerbe bis zum Jahre 2023 setzen aktuell weniger als ein Drittel der Unternehmen die dazugehörigen Technologien ein 2. Bisher findet die Anwendung überwiegend im Rahmen von Pilotprojekten zur Erprobung der technischen Machbarkeit statt. Eine weitläufige, systematische Erschließung und Umsetzung von Anwendungen sowie eine Einbettung in eine Gesamtstrategie fehlen. Dies begründet sich vor allem durch die Unkenntnis vieler Unternehmen über Einsatzpotenziale und die Implementierung von ML. Dies ist nicht zuletzt auf die Vielzahl verschiedener Methoden zurückzuführen, die jeweils spezifische Eignungsvoraussetzungen aufweisen.
Auswahl geeigneter Machine-Learning-Verfahren
Machine Learning umfasst verschiedene Algorithmen, welche in der Lage sind, selbständig aus Daten zu lernen und hieraus Wissen zu generieren. Häufig werden diese Verfahren in drei Lernarten eingeteilt: überwachtes Lernen („Supervised Learning“), unüberwachtes Lernen („Unsupervised Learning“) und verstärkendes Lernen („Reinforcement Learning“). Die einzelnen Lernarten sind für unterschiedliche Problem- und Zielstellungen sowie Ausgangsvoraussetzungen in den Unternehmen geeignet.
Sowohl beim überwachten als auch beim unüberwachten Lernen findet der Lernprozess auf Basis umfangreicher historischer Daten („Big Data“) statt. Verfahren dieser Lernarten bieten die Möglichkeit, selbständig Muster aus Daten zu erkennen und entsprechende Regeln abzuleiten, welche diese Muster möglichst gut repräsentieren und verallgemeinern. Die Algorithmen werden hierbei zunächst mit ausgewählten Daten trainiert und können anschließend zur Vorhersage neuer Fälle eingesetzt werden. Trotz dieser datenseitigen Gemeinsamkeit verfolgen beide Lernarten unterschiedliche Zielstellungen.
Im überwachten Lernen besteht das Ziel darin, eine oder mehrere unbekannte Zielvariablen mithilfe von bereits bekannten Eingangsvariablen vorherzusagen. Das Training dieser Verfahren findet auf Basis von Daten statt, in denen sowohl Eingangsvariablen als auch Zielvariablen bereits bekannt sind („Labeled data“) und entsprechende statistische Zusammenhänge aus dem Datensatz erkannt werden können. Das überwachte Lernen eignet sich somit grundsätzlich für Problemstellungen, bei denen gezielt bestimmte Informationen vorausgesagt werden sollen und „gelabelte“ Trainingsdaten in ausreichender Qualität und Umfang vorliegen, beispielsweise aus historischen Aufträgen. Die Problemstellung kann dabei entweder die Prognose kontinuierlicher Zielvariablen erfassen („Regression“), z. B. zukünftige Nachfragemengen oder die Dauer von Prozessen, oder auf die Vorhersage diskreter Variablen abzielen („Klassifizierung“), z. B. den Wartungszustand einer Anlage oder die Segmentierung von Materialien und Lieferanten nach bestimmten Eigenschaften. Die Vorhersagequalität steigt im Allgemeinen nicht nur mit dem Umfang des Trainingsdatensatzes, sondern auch mit der Anzahl möglichst problemspezifischer Eingangsvariablen, welche aus dem Problemverständnis im Vorfeld entsprechend identifiziert und ggf. aus verschiedenen Datenquellen zusammengeführt werden müssen.
Beim unüberwachten Lernen wird die Zielstellung verfolgt, Datensätze eigenständig auf Muster und verborgene Strukturen zu untersuchen und nach bestimmten Eigenschaften zu segmentieren. Die Trainingsdaten müssen in diesem Fall nicht über bereits bekannte Zielvariablen verfügen. Bekannte Unterkategorien sind die Clusteranalyse, bei denen Fälle mithilfe von Ähnlichkeitsmetriken in Gruppen eingeteilt werden sollen, und die Assoziationsregelanalyse, bei denen Korrelationen zwischen bestimmten Ereignissen detektiert werden sollen. Der Einsatz vom unüberwachten Lernen kann für Problemstellungen lohnenswert sein, bei denen komplexe Massendaten zunächst auf unbekannte Muster untersucht oder in bestimmte Kategorien eingeteilt werden sollen. Mögliche Anwendungsfälle in Unternehmen sind z. B. das Clustern von Komponenten anhand ihres Abrufverhaltens aus dem Lager, um darauf basierend Bereitstellungskonzepte zu optimieren oder die Identifizierung häufiger Störungskombinationen, welche zu Stillstandszeiten in der Produktion führen. Unüberwachten Lernen kann zudem für Fälle geeignet sein, in denen überwachtes Lernen aufgrund fehlender „gelabelter“ Datensätze nicht anwendbar ist.
Ein Ansatz, der keiner historischen Daten bedarf, ist das verstärkende Lernen. Ziel ist es hierbei, eine definierte Problemstellung durch einen Softwareagenten lösen zu lassen, wobei der optimale Lösungsweg vorab nicht bekannt ist. Der Lernprozess des Agenten findet in einer realen oder virtuellen Lernumgebung, z. B. in einem Simulationsmodell, iterativ über ein „Trial-and-Error“-Prinzip statt, bei dem der Agent nach jeder Handlung eine Rückmeldung aus dieser Umgebung erhält. Gute Lösungsansätze werden hierbei belohnt, schlechte Ansätze bestraft, wobei der Agent eine Maximierung der Belohnung erzielen soll. Verstärkendes Lernen eignet sich für Problemstellungen, bei denen keine Trainingsdaten zur Verfügung stehen, aber eine entsprechende Lernumgebung verfügbar ist. Anders als das überwachte und unüberwachte Lernen erkennen und approximieren solche Verfahren nicht nur Muster in bestehenden Daten, sondern sind auch geeignet, optimierende, ggf. auch unkonventionelle Lösungswege zu finden. Sie bieten daher das große Potenzial, Problemstellungen effizienter und auch unter unvollständigen und unsicheren Informationslage zu lösen, für die bislang klassische mathematische Optimierungsverfahren und Heuristiken genutzt wurden. Geeignete Anwendungsfälle ergeben sich u. a. in der Identifikation optimaler Transportrouten, Maschinenbelegungen und Lagerplätze sowie grundsätzlich für autonome Systeme und in der Robotik.
Für jede der genannten Lernarten existieren eine Vielzahl verschiedener Verfahren (siehe Bild 1),

Bild 1 Ausgewählte Lernarten und Verfahren von ML mit exemplarischen Anwendungsfällen.
Foto: Verfasser
welche sich in ihren Anwendungsvoraussetzungen erheblich unterscheiden.
Für einen erfolgreichen Einsatz der Algorithmen sind daher die Anforderungen der jeweiligen Problemstellung gezielt zu bewerten. Im Bereich des überwachten Lernens unterscheiden sich die Verfahren u. a. hinsichtlich der Anforderungen an die Ziel- und Eingangsvariablen und des benötigten Trainingsdatenumfangs, ihrer Performanz, Prognosegenauigkeit, Robustheit und Interpretierbarkeit. Beispielweise weisen entscheidungsbaumbasierte Verfahren eine hohe Eignung für Klassifizierungsprobleme auf. Diese Verfahren können verschiedene Typen von Eingangsvariablen auch ohne vorherige Normierung verarbeiten. Ferner sind sie auch bei kleinen Datensätzen einsetzbar und vergleichsweise gut interpretierbar. Auf der Data-Science-Plattform „kaggle“ gehören sie zu den am häufigsten eingesetzten Verfahren. Einige Verfahren, wie „Gradient Boosting Machines“, sind beispielsweise auch auf unvollständige Daten anwendbar; andere Verfahren, wie klassische Regressionsmodelle, hingegen nicht. Künstlich Neuronale Netze (KNN) sind prädestiniert für das Erlernen sehr komplexer Datenstrukturen, weshalb sie sich u. a. in der Bild-, Text- und Spracherkennung etabliert haben. Ihr Einsatz setzt vergleichsweise große Trainingsdatensätze voraus, die zudem normiert sein sollten. Ihre Interpretierbarkeit ist jedoch eher gering. Bei der Auswahl geeigneter ML-Verfahren ist daher häufig zwischen verschiedenen Eigenschaften abzuwägen. So führt beispielsweise eine hohe Prognosegenauigkeit aufgrund der dazu notwendigen komplexen Modellstruktur in der Regel zu einer geringeren Interpretierbarkeit der trainierten Modelle.
Aufgrund der individuellen Vorteile werden Problemstellungen oft durch eine Kombination von Verfahren der unterschiedlichen Lernarten gelöst. Grundsätzlich kann dabei festgehalten werden, dass ML insbesondere für komplexe Entscheidungsprozesse mit vielen Restriktionen, dynamischen Umfeldbedingungen und/oder hoher Unsicherheit geeignet ist. Hierbei handelt es sich oftmals um Entscheidungssituationen, die aktuell entweder mit hohen manuellen Anstrengungen oder nur ungenügend mit klassischen modellbasierten Ansätzen gelöst werden können.
Trotz der bereits hohen Anzahl verfügbarer Verfahren entwickelt sich ML mit einer hohen Geschwindigkeit weiter. Derzeitige Forschungsfelder umfassen insbesondere die Entwicklung transparenter Lernverfahren („Erklärbare KI“), die Entwicklung von sog. „Grey-Box-Verfahren“, die eine bessere Integration von menschlichem Wissen in die Modelle ermöglichen sollen sowie Ansätze zur Automatisierung des gesamten Entwicklungsprozesses von ML-Modellen („Auto-ML“).
Machine Learning zur Zuverlässigkeitssteigerung von Logistiknetzwerken
In Hinblick auf die steigenden Anforderungen an Zuverlässigkeit und Effizienz industrieller Lieferketten müssen deren einzelne Prozessabschnitte stärker synchronisiert werden, um eine hohe Auslastung der Infrastruktur und Ressourcen sowie eine Reduzierung von Wartezeiten zu gewährleisten – auch im Falle von Störereignissen. Machine Learning bietet ein hohes Potenzial zur Bewältigung dieser Herausforderungen, indem Ineffizienzen und Konflikte in den logistischen Netzwerken bereits im Voraus erkannt werden. In dem kürzlich abgeschlossenen Forschungsprojekt SMECS („Smart Event Forecast for Seaports“) hat das Fachgebiet Logistik der TU Berlin gemeinsam mit der DB Cargo AG und der Kühne Logistics University den Einsatz von ML für diese Problemstellung anhand intermodaler Transportketten untersucht. Als Anwendungsfall dienten dazu die verschiedenen Transport- und Umschlagsprozesse von Seefrachtcontainern im kombinierten Verkehr Straße-Schiene vom Verlader bis zum Seehafen („maritimer Vorlauf“). Hierfür wurde in dem Projekt ein KI-System entwickelt, welches vor Abfahrt beim Verlader die Ankunftszeiten von Transportaufträgen an wichtigen Prozessschnittstellen prognostiziert („Estimated Time of Arrival“, ETA), darauf basierende Störungen entlang der logistischen Kette detektiert und geeignete akteursspezifische Maßnahmen ausgibt.
Zur Realisierung der akteurs- und prozessübergreifenden ETA-Prognose wurde die komplexe Gesamtkette in verschiedene ML-bezogene Teilprobleme zerlegt, für die jeweils individuelle Vorhersagemodelle entwickelt wurden. Hierzu gehörten neben Prognosemodellen für den Straßen- und Schienentransport auch Modelle für Umschlags- und Rangierprozesse in den logistischen Knotenpunkten. In Abhängigkeit der jeweiligen Problemarten kamen dabei verschiedene ML-Verfahren des überwachten Lernens zum Einsatz. Da die optimalen Verfahren im Vorhinein häufig nicht bekannt waren, mussten diese im Rahmen eines iterativen Entwicklungsprozesses mit mehrfacher Modellvalidierung bestimmt werden. Für die Vorhersage von Ankunftszeiten von Güterzügen hat sich der Einsatz von entscheidungsbaumbasierten Ansätzen, wie „Random Forest“ und „Gradient Boosting“, bewährt, da diese Verfahren die Vielzahl unterschiedlicher Einflussfaktoren optimal in die Prognose integrieren konnten und auch für vergleichsweise kleine Trainingsdatensätze geeignet sind. Die Prognose des voraussichtlichen Anschlusszuges in Rangierbahnhöfen, z. B. infolge von Verspätungen, konnte hingegen durch spezielle Klassifikationsverfahren für ordinale Zielvariablen, sog. „Ordinal Random Forests“, optimal bewerkstelligt werden. Darüber hinaus wurden auch Verfahren des unüberwachten Lernens in der Entwicklung eingesetzt, z. B. um häufig gemeinsam auftretende Störungsarten und entsprechende Störungsmuster zu identifizieren.
Neben der Auswahl passender Verfahren bildet die Identifizierung und Einbindung geeigneter Datenarten einen zentralen Erfolgsfaktor zur Entwicklung von ML-Lösungen. Im SMECS-Projekt wurden dazu historische Daten aus insgesamt 15 verschiedenen IT-Systemen unterschiedlicher Akteure für 4 Jahre in die Prognose miteinbezogen, u. a. 50.000 Schienentransporte und 100.000 Straßentransporte. Die Datenbeschaffung fand zunächst für mehrere repräsentative Pilotrelationen statt. Für jedes Teilproblem wurden die relevantesten Faktoren mit Einfluss auf die Prozessdauer bestimmt und in Form von Eingangsvariablen in das Modell integriert. Im Bereich des Schienentransports gehörten dazu u. a. Daten zum Fahrplan, Personaleinsatz, zu Zug- und Lokeigenschaften, Baustellen, geplanten betrieblichen Prozessen sowie auch zeitliche Faktoren und Wetterbedingungen.
Im Anschluss an die Entwicklung der prozessbezogenen Teilmodelle erfolgte deren Integration in ein Gesamtsystem, welches die Berechnung einer „Door-to-Port“-ETA für einen bestimmten Transportauftrag ermöglicht. Diese Lösung zeigt im Vergleich zu bisher verfügbaren Prognoseansätzen sehr vielversprechende Ergebnisse. Für teilweise mehrtägige Gesamtdauern des maritimen Vorlaufs belaufen sich die Abweichungen der Prognosen zu den tatsächlichen Zeiten für viele Aufträge im zweistelligen Minutenbereich – auch im Falle von störungsbedingten Verspätungen. Für den Teilprozess des Schienentransportes kann dabei beispielsweise die Ankunftszeit auf der Relation von München bis zum Rangierbahnhof in Maschen (mittlere Fahrzeit zirka 15 h) zum Zeitpunkt der Abfahrt mit einer Genauigkeit von 86 % in einem +/- 10 %-Abweichungsintervall richtig vorhergesagt werden.
Das entwickelte Prognosesystem des SMECS-Projektes wurde zusätzlich um eine regelbasierte Entscheidungsunterstützung ergänzt, welche in Abhängigkeit der ETA-Prognose Anschlusskonflikte der einzelnen Prozesse automatisch detektiert und den beteiligten Akteuren Empfehlungen für optimierende Maßnahmen bereitstellt. Hierdurch werden die Akteure zu einer frühzeitigen Erkennung von potenziellen Störungen und Prozessverzögerungen sowie zum Ergreifen zielgerichteter Handlungen befähigt. Der im Projekt entwickelte Prototyp wurde in Form einer webbasierten Anwendung für die Öffentlichkeit bereitgestellt und bietet den Nutzern die Möglichkeit, die Potenziale von ML am Beispiel ausgewählter historischer, anonymisierter Transportaufträge zu erproben (siehe Bild 2).
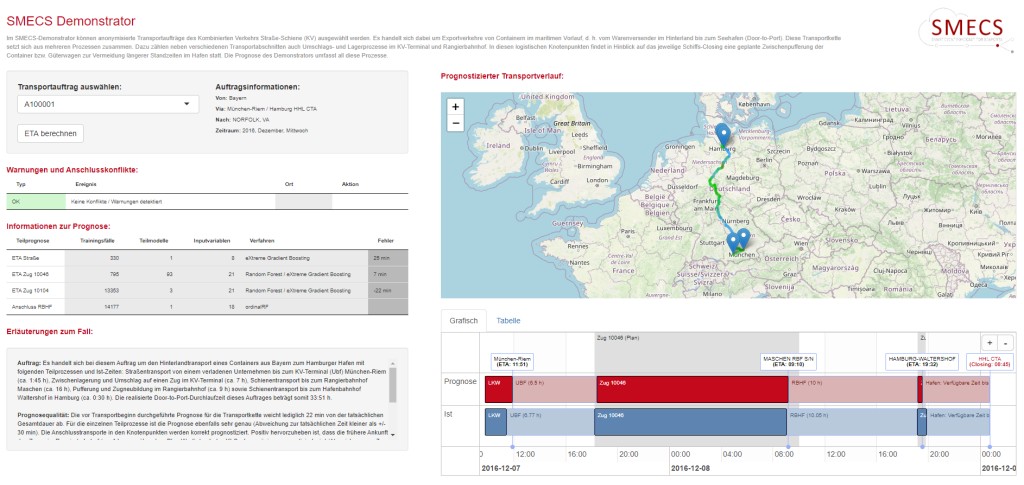
Erfolgsfaktoren bei der Umsetzung von Machine-Learning-Projekten
Die positiven Ergebnisse von umgesetzten Use-Cases, wie im SMECS-Projekt, verdeutlichen die Potenziale der ML-Technologie für Entscheidungsprobleme in Logistiknetzwerken. Gleichzeitig zeigen sie auch die vielschichtigen Herausforderungen, die bei einer erfolgreichen Umsetzung dieser Vorhaben zu bewältigen sind.
Ein immanenter Erfolgsfaktor stellt die Verfügbarkeit von Daten dar – sowohl im Rahmen der Entwicklung als auch im späteren Live-Betrieb. Die Ergebnisqualität der mittels ML entwickelten Algorithmen hängt maßgeblich von den berücksichtigten Eingangsdaten ab. Hierzu müssen oft hohe Barrieren in Form eines Silodenkens innerhalb von Organisationen und wettbewerbsbezogener Vorbehalte bei unternehmensübergreifenden Vorhaben überwunden werden. Eine transparente Kommunikation des angestrebten Dateneinsatzes und der damit einhergehenden Mehrwerte sowie eine Festlegung nicht relevanter Informationen, z. B. von Kundendaten, sind hierbei hilfreich. Die Einbindung eines neutral agierenden Partners, wie in Form von wissenschaftliche Institutionen, kann bei der Datenbereitstellung das notwendige Vertrauen für alle Beteiligten schaffen.
Neben den organisatorischen Gründen ist die Verfügbarkeit auch oft aus technischen Gründen beschränkt, z. B. weil nicht alle Datenquellen für den benötigten Zeitpunkt erhoben oder vorgehalten wurden oder die Datenqualität nicht ausreichend ist. Für eine frühzeitige und umfassende Kenntnis über die verfügbaren Datenquellen empfiehlt sich die intensive Einbindung von Prozessverantwortlichen und IT-Fachabteilungen. Gemeinsam können schon zu Beginn innerhalb von Daten-Workshops erste Relevanz- und Qualitätsbewertungen durchgeführt sowie Alternativlösungen identifiziert werden. Zur Sicherstellung der Ergebnisgüte sollte die Einbindung dieser Experten auch in weiteren Phasen eines ML-Projektes erfolgen – vor allem im Rahmen einer zielorientierten Identifikation von relevanten Einflussfaktoren („Feature Engineering“) und bei der Ergebnisbewertung aus Praxissicht („Model Validation“).
Entsprechend der Neuartigkeit des gewählten Ansatzes sind auch die sozialen Herausforderungen nicht zu vernachlässigen. Insbesondere das partielle Übertragen von Aufgaben an eine „Maschine“ und die teilweise schwierige Interpretation der durch die Algorithmen gefundenen Muster („Black-Box-Modelle“) können die Akzeptanz zur Nutzung der ML-Lösungen bei den betroffenen Mitarbeitern erschweren. Um dem entgegen zu wirken, muss ein Verständnis über die Funktionsweise, Fähigkeiten, aber auch Grenzen der neuen Technologien geschaffen werden. Neben der Befähigung der Mitarbeiter für den Umgang mit Anwendungen aus dem KI-Bereich, welche zukünftig immer mehr die Berufswelt prägen werden, wird dadurch auch ein Verständnis für die Relevanz von Datenqualität geschaffen.
Insgesamt zeigt sich, dass ML-Vorhaben sowohl hinsichtlich der vorbereitenden Maßnahmen, wie bei der Identifikation relevanter Datenquellen, als auch bei der eigentlichen IT-Implementierung, insbesondere bei der Auswahl geeigneter Modellkonfiguration und Methoden, individuelle Lösungsentwicklungen erfordern. Eine tiefgreifende Auseinandersetzung mit der jeweiligen betrieblichen Problemstellung und deren Umfeld einerseits sowie mit den technologischen Eignungsvoraussetzungen von ML andererseits trägt dabei maßgeblich zum Projekterfolg bei.
1 Junge, A.L.; Verhoeven, P.; Reipert, J.; Mansfeld, M. (2019): Pathway of digital transformation in logistics. Hg. v. Straube, F. Berlin: Universitätsverlag der TU Berlin.
2Seifert, I.; Bürger, M.; Wangler, L.; Christmann-Budian, S.; Rohde, M.; Gabriel, P.; Zinke, G. (2018): Potenziale der Künstlichen Intelligenz im produzierenden Gewerbe in Deutschland. Berlin: iit-Institut für Innovation und Technik in der VDI / VDE Innovation + Technik GmbH.
Prof. Dr.-Ing. Frank Straube (Leiter des Bereichs Logistik am Institut für Technologie und Management an der TU Berlin), Manuel Weinke und Peter Poschmann (Beide wissenschaftlicher Mitarbeiter am Fachgebiet Logistik, Institut für Technologie und Management der TU Berlin)








