Fast wie Magie: Forscher wandeln Gedanken in Sprache um
Forschende entwickeln eine Methode, um Gedanken in Sprache umzuwandeln – und zwar nahezu in Echtzeit dank KI und Gehirn-Computer-Schnittstelle.

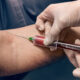
Forscher verbinden Anns Hirnimplantat mit dem Sprachsynthesizer-Computer. Die Patientin konnte damit wieder sprechen.
Foto: Noah Berger
Ein US-amerikanisches Forschungsteam hat eine Technologie entwickelt, die Gedanken von Menschen mit Sprachlähmung nahezu in Echtzeit in hörbare Sprache umwandelt. Grundlage ist eine Kombination aus Gehirnsignalen und Künstlicher Intelligenz. Ziel ist es, Betroffenen eine natürlichere Kommunikation zu ermöglichen.
Inhaltsverzeichnis
Gedanken werden hörbar
Wenn der Körper nicht mehr mitmacht, schweigt oft auch die Sprache. Für Menschen mit schweren Lähmungen bedeutet das: Isolation. Ein interdisziplinäres Team der University of California in Berkeley und San Francisco will das ändern. Mithilfe einer neuen Gehirn-Computer-Schnittstelle (Brain-Computer Interface, kurz BCI) gelingt es ihnen, Gedanken in gesprochene Sprache zu übertragen – fast in Echtzeit.
Die Technik basiert auf neuronalen Daten, also elektrischen Signalen im Gehirn, die beim Versuch zu sprechen entstehen. Künstliche Intelligenz (KI) übersetzt diese Muster direkt in akustische Sprache. Ein solches System kann Menschen mit Sprachverlust neue Wege der Kommunikation eröffnen.
Was ist neu an dieser Methode?
Das Besondere an der aktuellen Entwicklung ist die Geschwindigkeit, mit der das System Sprache erzeugt. Frühere Ansätze benötigten mehrere Sekunden, um einen gesprochenen Satz zu rekonstruieren. Jetzt dauert es nur noch etwa eine Sekunde vom Gedanken bis zur hörbaren Stimme.
„Unser Streaming-Ansatz bringt die gleiche schnelle Sprachdecodierungskapazität von Geräten wie Alexa und Siri in Neuroprothesen ein“, erklärt Gopala Anumanchipalli, Assistenzprofessor für Elektrotechnik und Informatik an der UC Berkeley.
Die Methode arbeitet ähnlich wie Sprachassistenten, allerdings mit einem entscheidenden Unterschied: Die Eingabe erfolgt nicht per Mikrofon, sondern direkt über Gehirnsignale. Diese stammen aus dem motorischen Kortex – dem Bereich des Gehirns, der Bewegungen wie das Sprechen steuert.
So funktioniert das Gedanken-zu-Sprache-System
Die Versuchsperson „Ann“, die bereits an früheren Studien teilnahm, konnte durch eine hohe Rückenmarksverletzung nicht mehr sprechen. Trotzdem erzeugt ihr Gehirn beim Versuch, einen Satz zu artikulieren, typische Aktivitätsmuster.
Die Forschenden zeigten ihr auf einem Bildschirm einen Satz wie: „Hey, wie geht es dir?“ und baten sie, diesen stumm zu sprechen. Das System zeichnete dabei die neuronalen Signale auf und trainierte ein KI-Modell, um diese mit dem angestrebten Satz abzugleichen. Ein vortrainiertes Text-zu-Sprache-System erzeugte anschließend die akustische Sprache.
Dabei verwendete das Team Aufnahmen von Anns Stimme aus der Zeit vor ihrer Verletzung. So klang die synthetisierte Stimme besonders authentisch.
Hier wird Ihnen ein externer Inhalt von youtube.com angezeigt.
Mit der Nutzung des Inhalts stimmen Sie der Datenschutzerklärung
von youtube.com zu.
Ein System für verschiedene Schnittstellen
Ein großer Vorteil der neuen Methode: Sie ist flexibel einsetzbar. Die Forschenden testeten das System mit unterschiedlichen Sensoren – von Elektrodenarrays, die direkt auf der Gehirnoberfläche liegen, bis zu sogenannten sEMG-Sensoren. Letztere messen Muskelaktivität im Gesicht und kommen ohne operative Eingriffe aus.
„Wir haben gezeigt, dass diese Technik nicht auf einen bestimmten Gerätetyp beschränkt ist“, betont Kaylo Littlejohn, Mitautor der Studie. Entscheidend sei vor allem ein klares Signal – dann könne der gleiche Algorithmus auf verschiedenen Plattformen genutzt werden.
Auch unbekannte Wörter werden erkannt
Ein weiterer Test überprüfte, ob das System auch Wörter erkennt, die es während des Trainings nicht gelernt hatte. Dazu nutzten die Forschenden Begriffe aus dem NATO-Alphabet wie „Bravo“ oder „Charlie“. Das System konnte diese zuverlässig in Sprache umwandeln.


„Das zeigt, dass unser Modell tatsächlich die grundlegenden Bausteine von Sprache versteht“, sagt Anumanchipalli. Es erkennt also nicht nur Muster, sondern kann neue Wörter korrekt generieren.
Die Bedeutung für die Betroffenen
Für Menschen wie Ann ist das mehr als eine technische Spielerei. Sie berichtete, dass sich das neue System natürlicher anfühle als frühere Methoden. „Ihre eigene Stimme nahezu in Echtzeit zu hören, verstärkte ihr Gefühl der Verkörperung“, sagt Anumanchipalli.
Die Technologie erlaubt es ihr, sich gezielter auszudrücken – mit Intonation, Pausen und Tonfall. Ziel der Forschenden ist es nun, auch diese feinen sprachlichen Nuancen besser aus den neuronalen Daten zu lesen.
Wie geht es weiter?
Die Ergebnisse sind vielversprechend, doch die Arbeit ist noch nicht abgeschlossen. Das Forschungsteam plant, den Algorithmus weiter zu verbessern. Künftig soll er auch Emotionen wie Freude oder Aufregung an der Sprachmelodie erkennbar machen.
„Wir versuchen, paralinguistische Merkmale wie Tonhöhe oder Lautstärke direkt aus der Gehirnaktivität zu rekonstruieren“, erklärt Littlejohn.
Langfristig soll die Technologie Menschen mit Sprachverlust ein möglichst natürliches Sprechen ermöglichen – so, als würden sie selbst sprechen.
Ein Beitrag von: